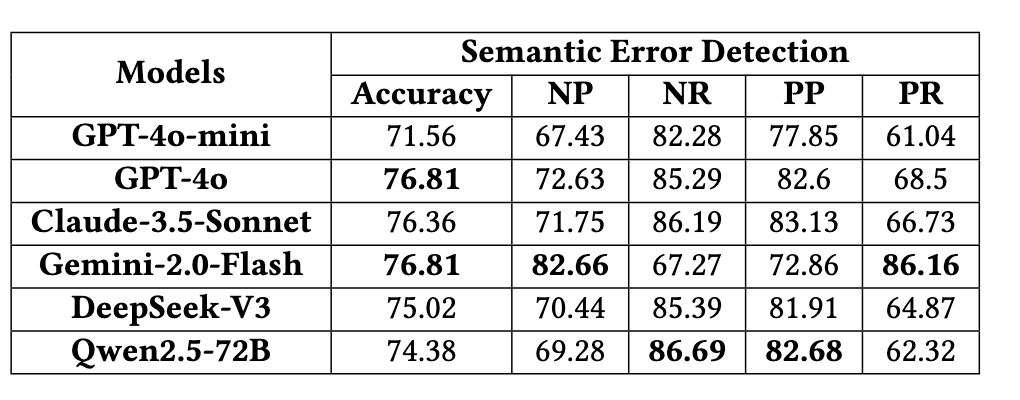
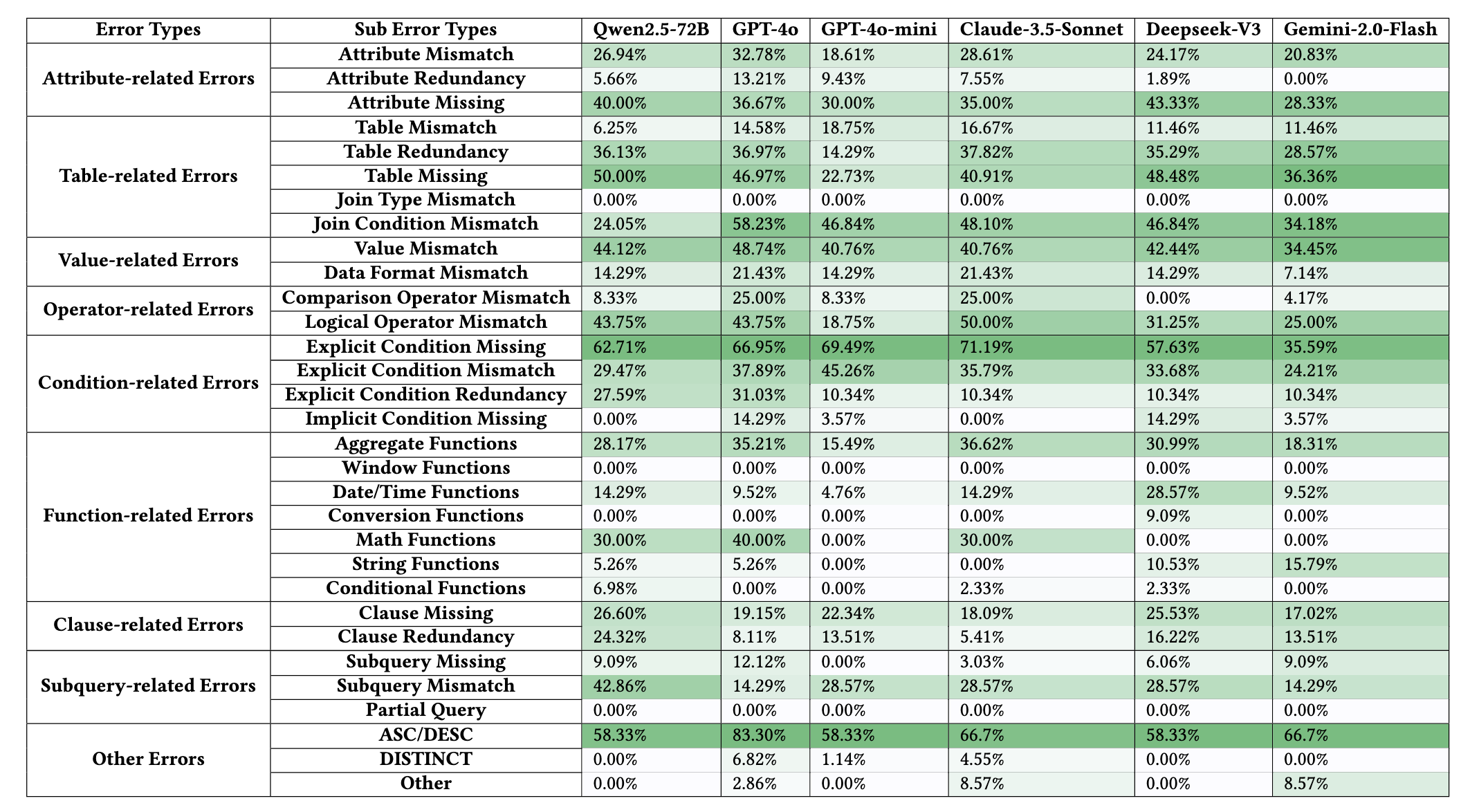
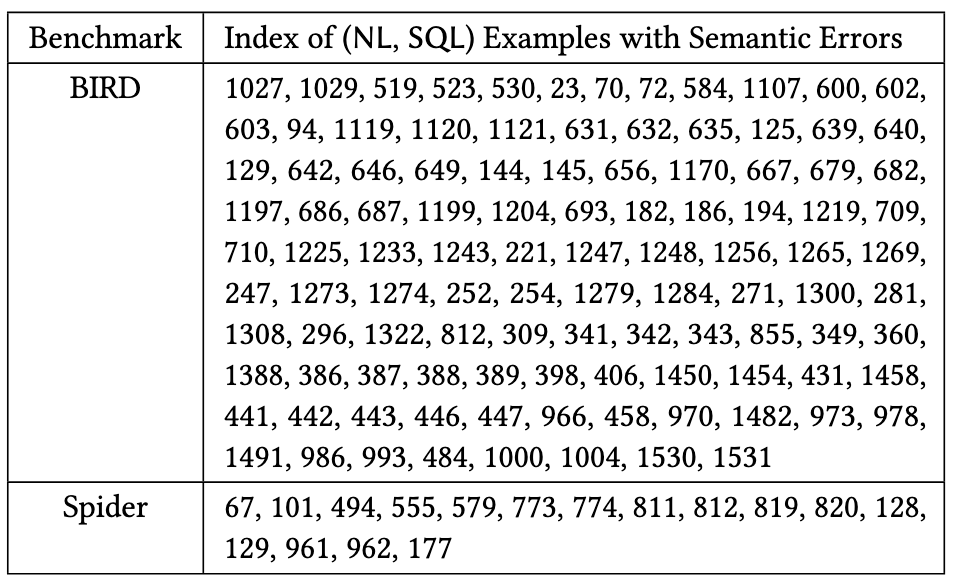
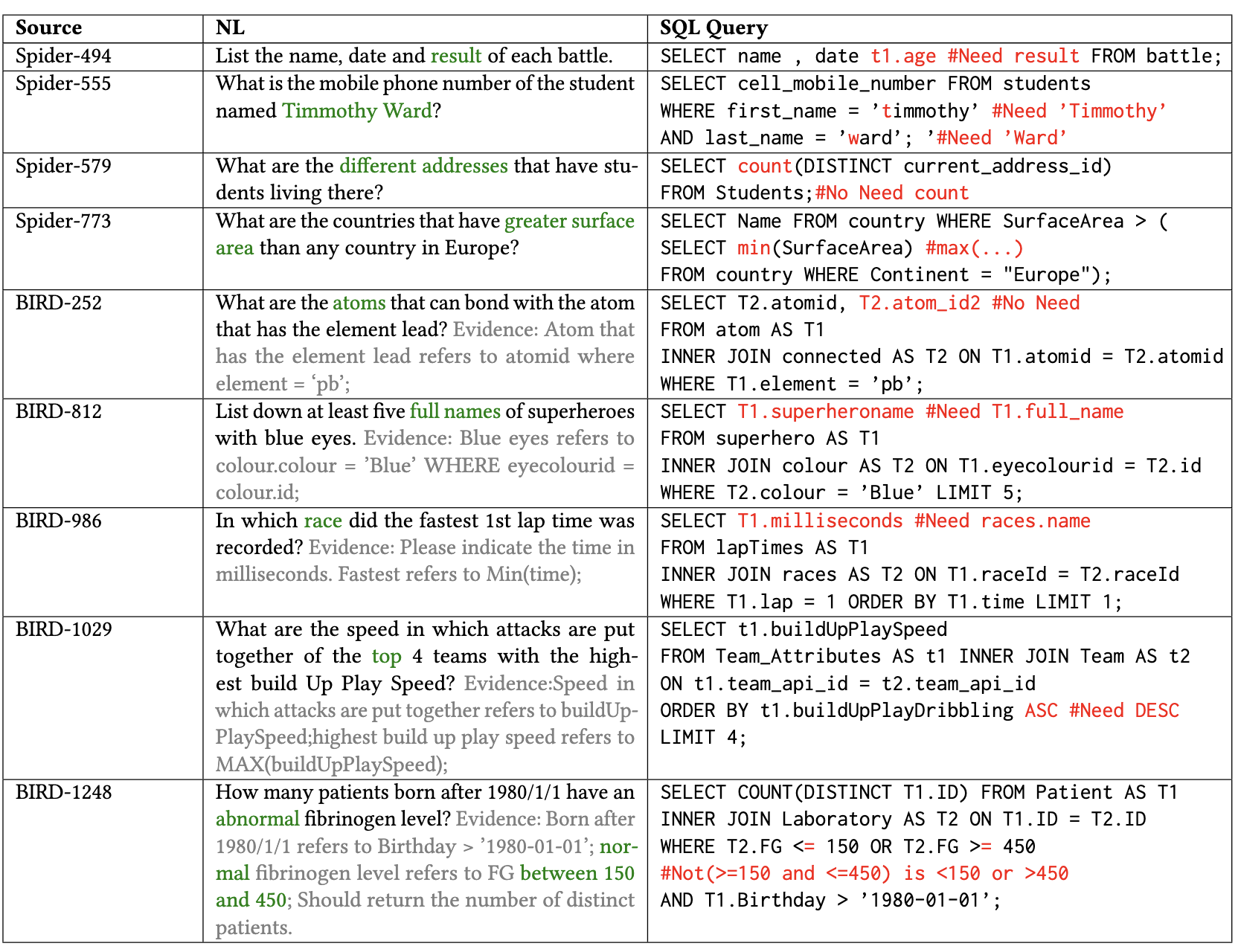
Error Taxonomy
The classification of semantic errors in NL2SQL is based on the structure of SQL queries, common translation mistakes, and their impact on query semantics. This approach allows for systematic error identification at various stages of query generation, helping to pinpoint where and why translation mistakes occur.
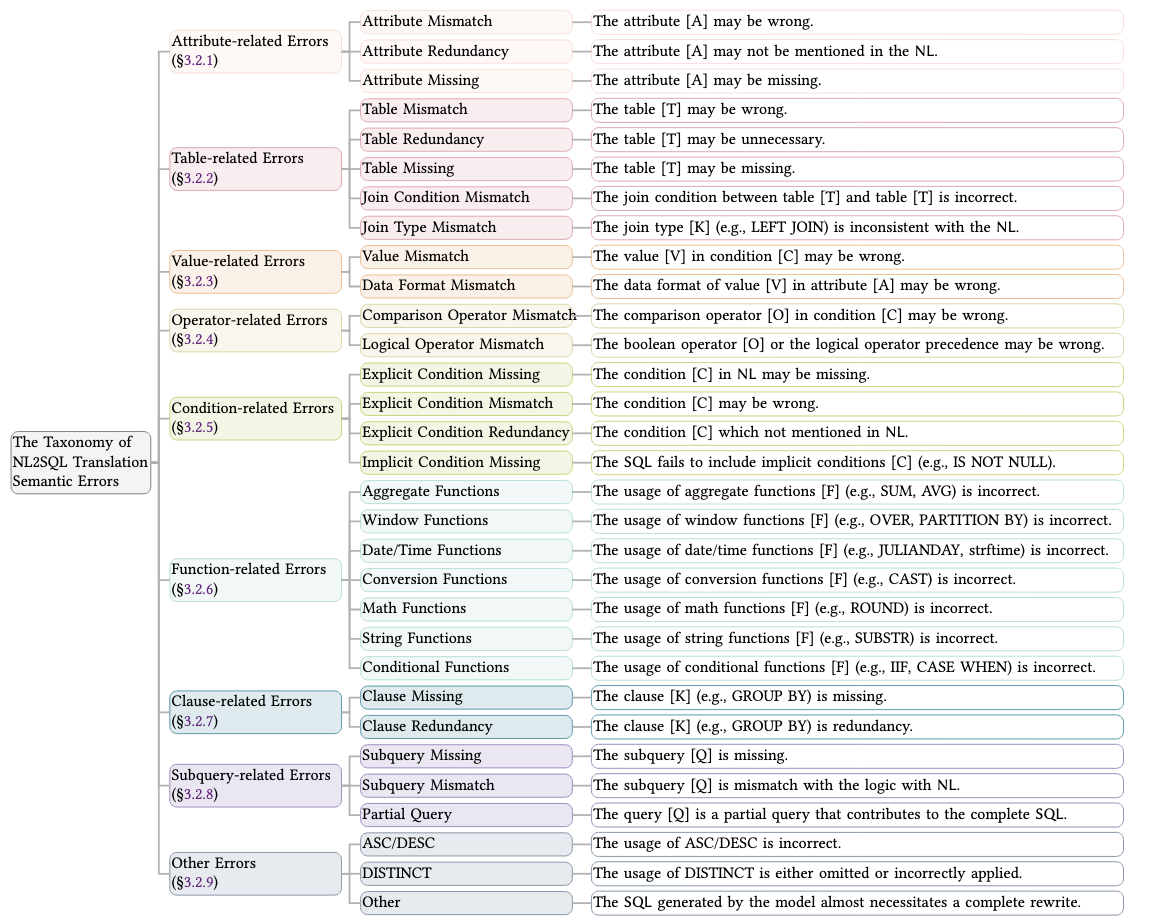
Our taxonomy classifies semantic errors into 9 main categories and 31 subcategories:
NL2SQL-BUGs Statistics
We collect 2,018 expert-annotated instances, each containing a natural language query, database schema, and SQL query. Among these instances, 1,019 are correct examples while 999 are incorrect examples with semantic errors. Each incorrect example is carefully annotated with detailed error types and explanations, providing a comprehensive resource for studying semantic errors in NL2SQL translation.
The statistics of NL2SQL-BUGs are shown in the following figure: